这篇文章主要目的是想介绍一下我在 Comfyui 里使用 GPT-4o 模型生图的经验。
其实之前我一般都是用cherrystudio调用API来出图,图个方便。那为啥还要用comfyui呢?主要是comfyui可以对模型的输出结果进行二次加工。
而且,GPT-4o 一次其实是可以输出4张图片的,也就是我们只需要花一次的钱,就可以得到4张图片。
我用cherrystudio的时候,虽然在提示词里指明了一次生成四张图,可惜每次都只能看到一张。可能是我用法不对?不过懒得研究了,还是用comfyui试试。
OK,下面进入正题。
用comfyui调用4o的API,首先需要装一个插件:ComfyUI-GPT-API
https://github.com/CY-CHENYUE/ComfyUI-GPT-API
安装方法,先打开comfyui目录里的custom_nodes子目录,然后在地址栏输入cmd进入命令行,再输入
git clone https://github.com/CY-CHENYUE/ComfyUI-GPT-API
插件成功下载之后,在进入ComfyUI-GPT-API目录,安装依赖。
pip install -r requirements.txt
如果你使用的comfyui便携包,我建议使用下面的命令安装(这样可以确保依赖安装到便携包的环境内):
你的comfyui目录\python_embeded\python.exe -m pip install -r requirements.txt
然后我们再来安装另一个插件:comfyui_LLM_party
https://github.com/heshengtao/comfyui_LLM_party
方法跟上面一样,在custom_nodes目录打开命令行
git clone https://github.com/heshengtao/comfyui_LLM_party.git
同样的,下载完成之后,进入comfyui_LLM_party目录,安装依赖
你的comfyui目录\python_embeded\python.exe -m pip install -r requirements.txt
依赖装好之后,还需要打开comfyui_LLM_party目录里的config.ing文件,设置一下模型和密钥。
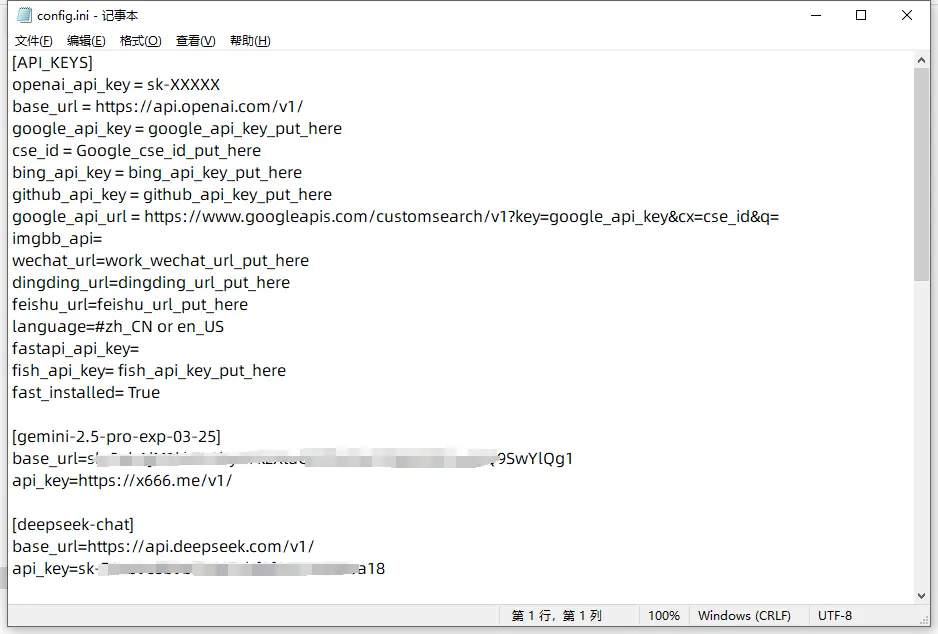
这里根据需要设置你手上的大模型 API ,我推荐用gemini,或者deepseek也可以。
装好这两个插件之后,就可以启动comfyui了。
这里我展示一下工作流的全景。

这个工作流的目的,就是通过GPT-4o按照提示词出图,然后,从模型回传的信息里提取出4张图片的URL,再转换成图片自动保存。
看上去很简单的需求,但是要在comfyui里一次完成,我还是摸索了一会。下面就来看看详情。
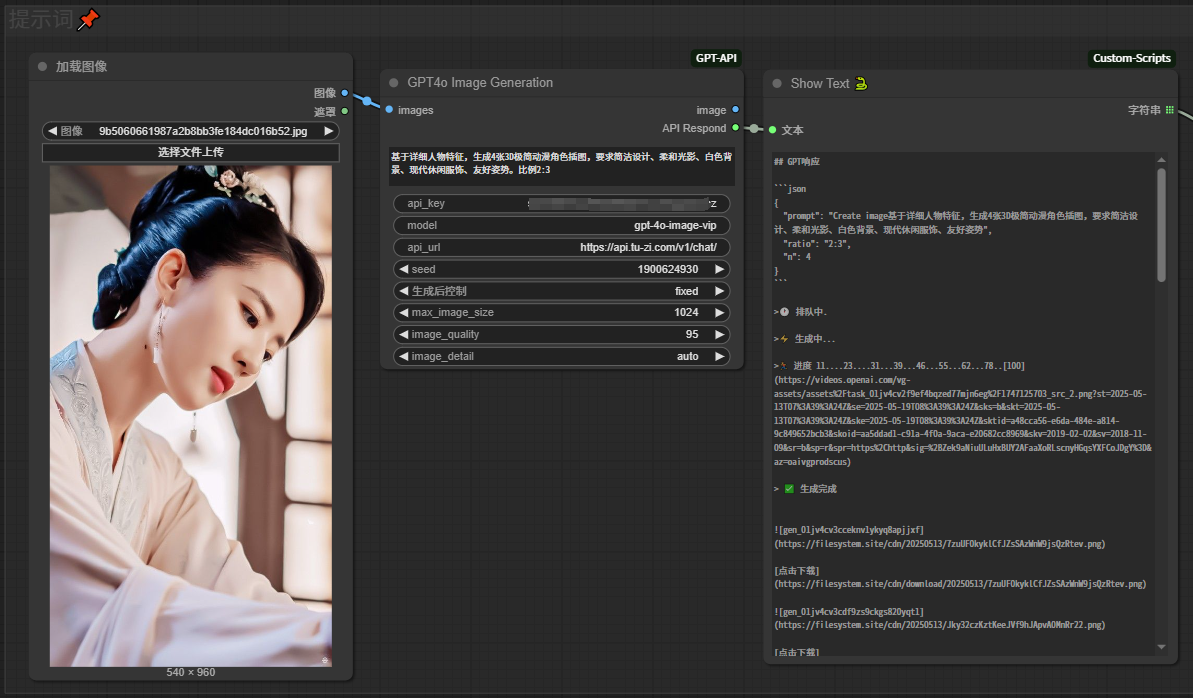
首先,加载一张图片,传给“GPT4o Image Generation”节点。同时在这个节点里写上提示词,填好API KEY、模型名称、API URL。
最右边,就是GPT4o 模型成功生成后返回的信息。如果这里直接在image那里拉出一个“保存图像”的节点,就只能得到一张图像,其他的要去那一堆信息里去找到图片地址然后一张张下载。
非常不优雅。
接下来,把模型返回的信息传给“提取字符串”节点,通过把开始和结尾分别设置成“生成完成”和“处理信息”,这样就得到只有图片URL的那一段信息,这样可以提高后面处理的成功率,也减少了token消耗。
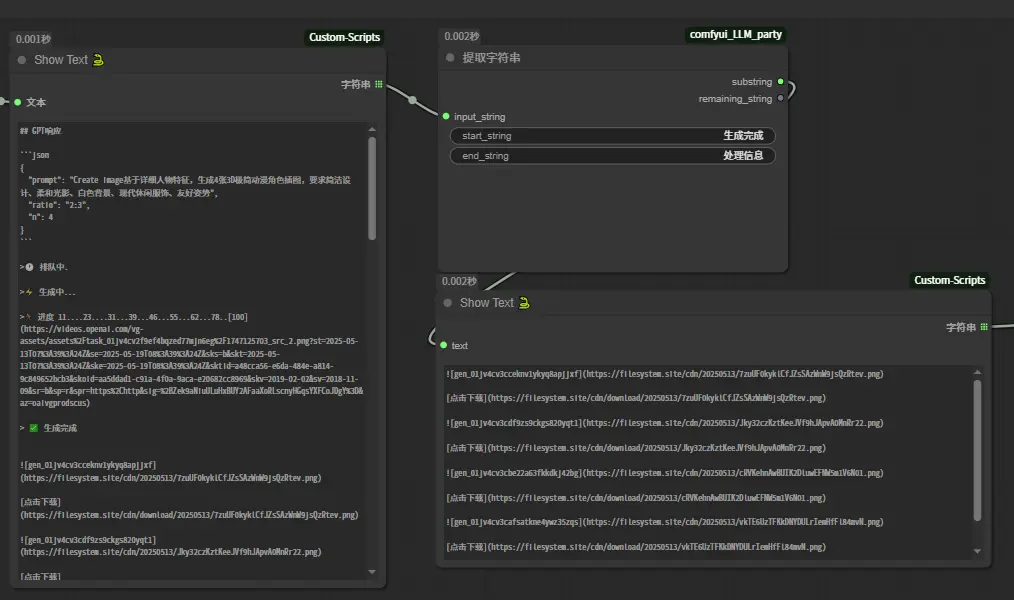
接下来,把只有图片URL的那一段信息,传给“API LLM通用链路”节点。这里的目的,是通过大语言模型,把图片URL进一步提纯。
参考提示词:把我输入的图片URL提取出来,只需要图片URL,不附加其他任何信息,每个URL后面用,隔开。
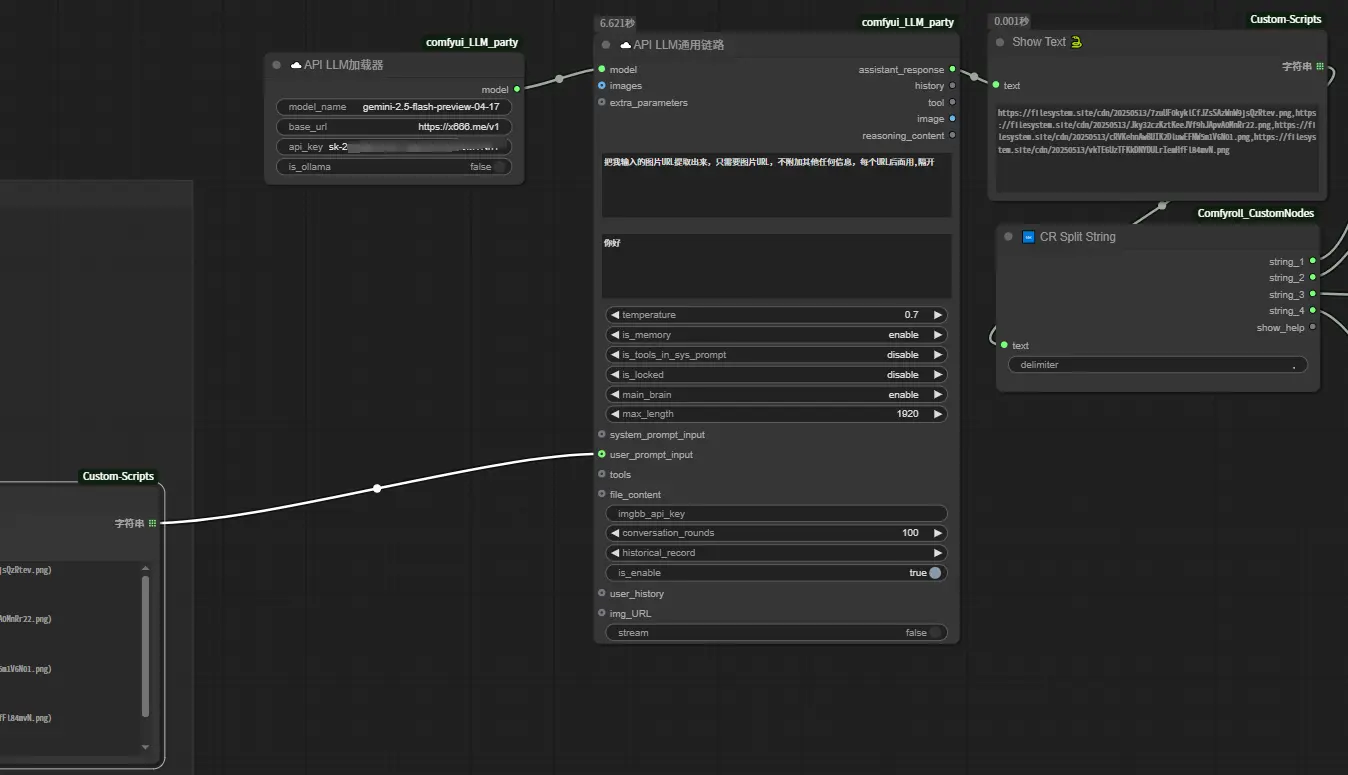
至此,我们就得到了一段只有4个图片URL的文本,URL之间用逗号隔开。然后使用“CR Split String”这个节点,把每张图片URL单独提取出来。
最后,使用“Load Image From Url (mtb)”这个节点,把图片URL还原成图片,再传给“保存图像”节点自动保存。
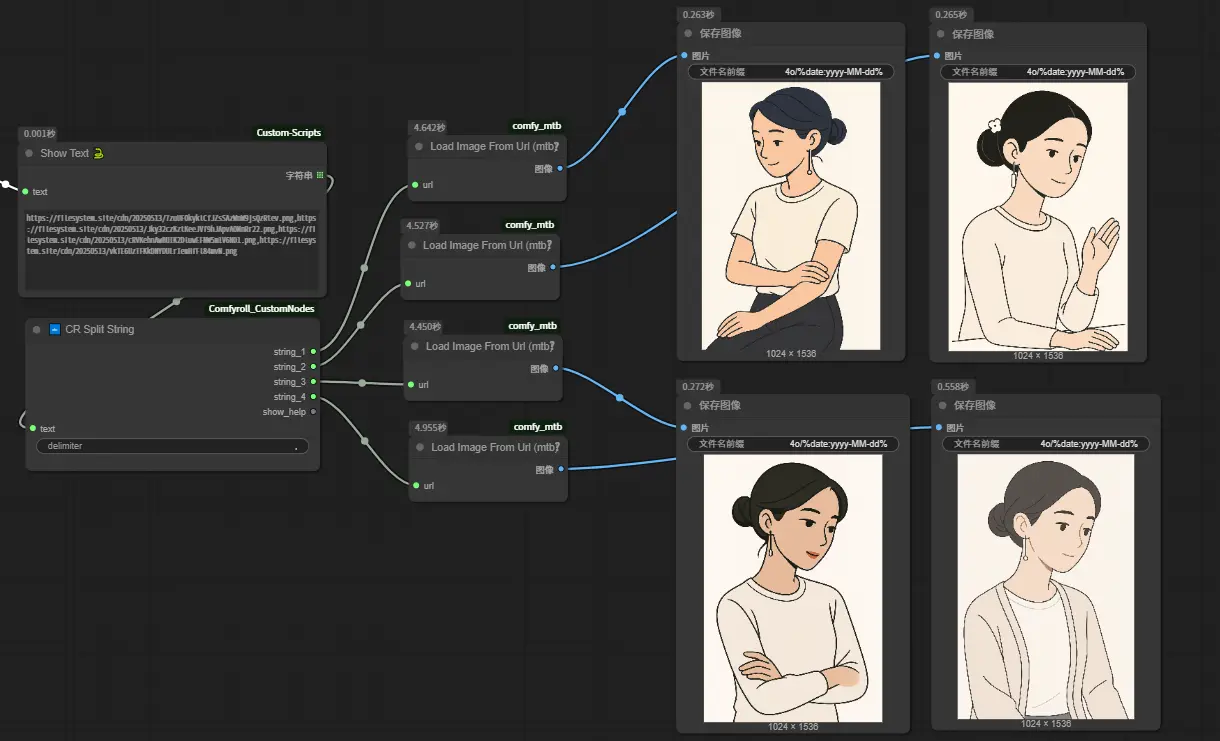
总结一下:
整个工作流原理其实很简单,就是先通过 4o 生图,再使用大语言模型把夹杂在大段文本中的图片URL提取出来,然后分别保存。
其实如果只是单纯想用 4o 生成图像,直接用cherrystudio这样的客户端很方便。不过comfyui的妙处就是它是一个基于工作流的、开源的AI图像生成软件,这样我们就可以基于工作流模式,完成很多奇妙的构想。
无论是把大语言模型作为中介,还是把 4o 这类模型生成的图片作为素材二次加工,或者把comfyui生成的图像交给 4o 进行加工,都可以达到1+1>2的效果。
工作流下载: