-
¶ 概述
Flux-Kontext-Pro 是一个强大的AI图像生成模型,支持基于文本提示和参考图像生成高质量图像。本项目提供了两种调用方式:
- Chat格式API (
chat_api.py) - 简化的聊天格式调用,参数较少 - 标准API (
flux_api.py) - 完整的API调用,支持所有参数配置
- 如果您是comfy-ui用户可以看这篇文章Comfyui中使用flux-Kontext-Pro
¶ 快速开始
¶ 环境要求
- Python 3.6+
- 网络连接
¶ API密钥配置
在使用前,请确保您有有效的API密钥(defalut分组)。
¶ 调用方式一:官方格式API (待开发完成)请先使用方案二、三
https://api.bfl.ml/scalar#tag/tasks/POST/v1/flux-pro
请查看官方文档,所有参数和官方文档一致。
¶ 生成图片
import http.client
import json
conn = http.client.HTTPSConnection("https://api.tu-zi.com")
payload = json.dumps({
"prompt": "ein fantastisches bild",
"width": 1024,
"height": 768,
"steps": 40,
"prompt_upsampling": False,
"seed": 42,
"guidance": 2.5,
"safety_tolerance": 2,
"interval": 2,
"output_format": "jpeg"
})
headers = {
'Authorization': 'Bearer {{YOUR_API_KEY}}',
'Content-Type': 'application/json'
}
conn.request("POST", "/flux/v1/", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))
¶ 调用方式二:Chat格式API
¶ 特点
- 简单易用,类似ChatGPT的消息格式
- 支持流式输出(不支持非流)
- 参数较少,适合快速原型开发
- 可接入第三方壳中调用(直接base64传图),如下图:
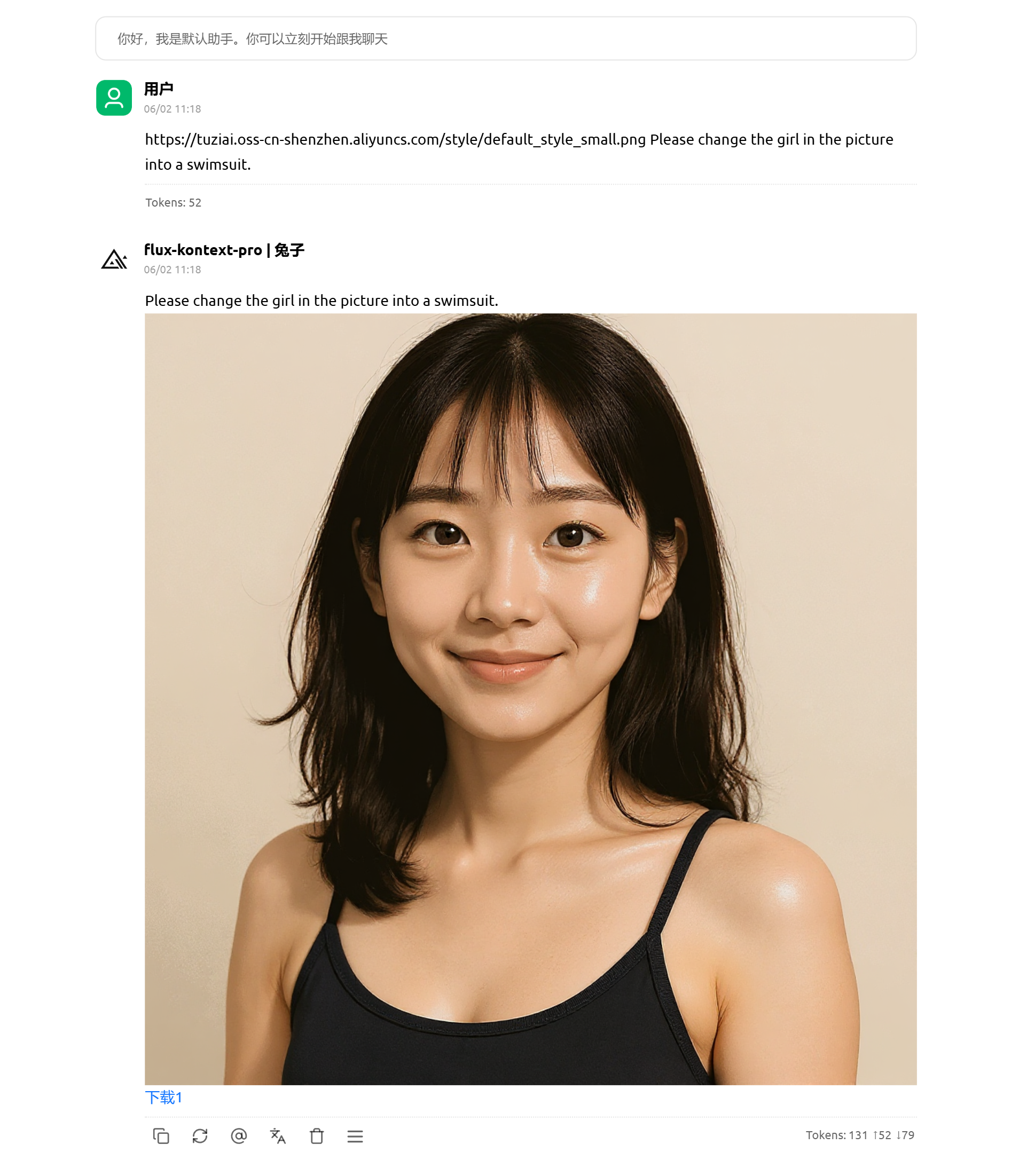
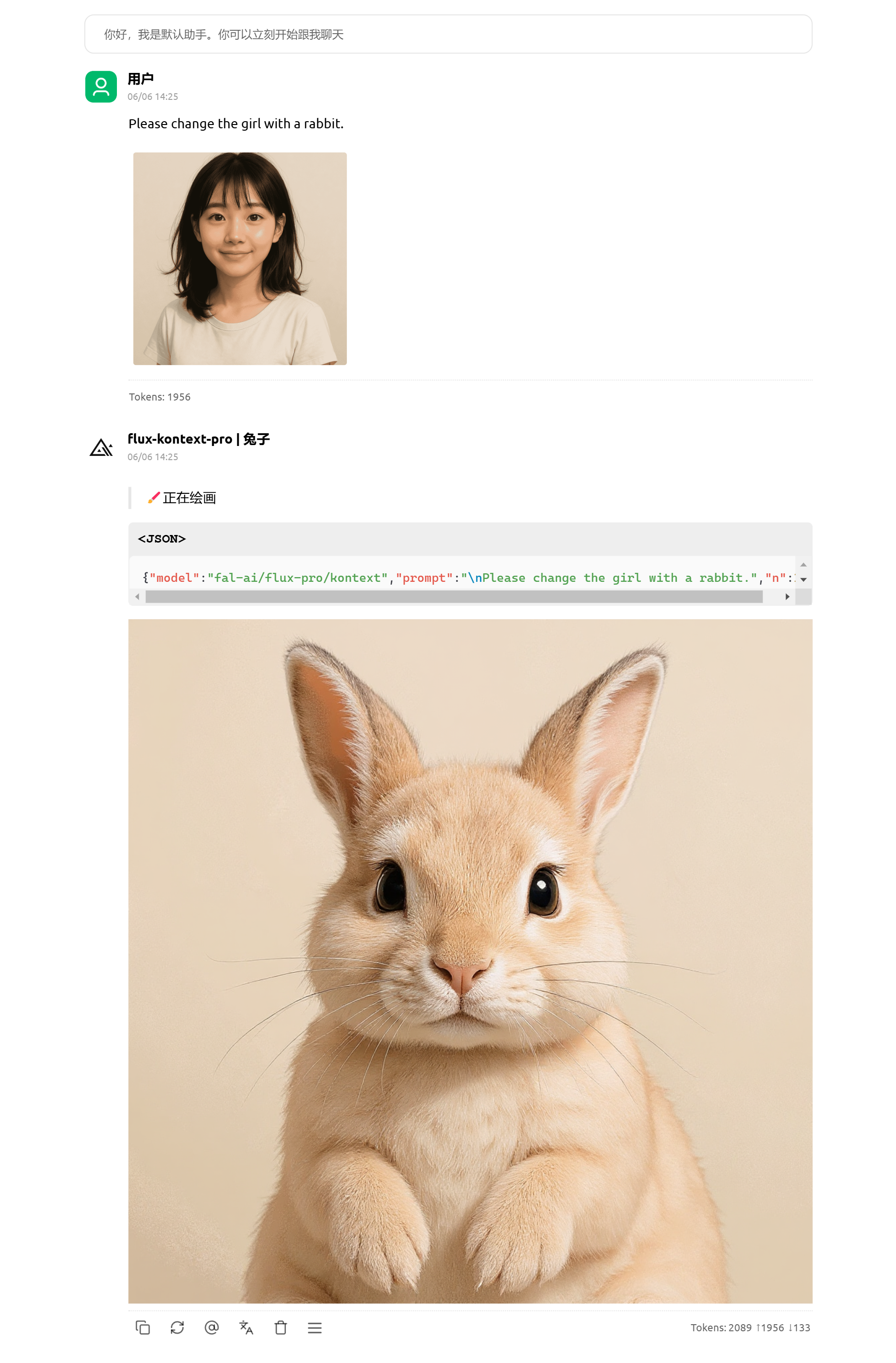
- 可接入Comfyui中调用,参考教程:Comfyui中使用flux-Kontext-Pro
¶ API使用示例(url传图)
import http.client
import json
def generate_image_with_chat_format(messages):
"""流式调用图像生成API"""
conn = http.client.HTTPSConnection("api.tu-zi.com", timeout=300)
payload = json.dumps({
"model": "flux-kontext-pro",
"messages": messages,
"stream": True
}, ensure_ascii=False).encode('utf-8')
headers = {
'Authorization': 'Bearer your-key',
'Content-Type': 'application/json; charset=utf-8'
}
conn.request("POST", "/v1/chat/completions", payload, headers)
res = conn.getresponse()
buffer = ""
while True:
chunk = res.read(1)
if not chunk:
break
buffer += chunk.decode('utf-8', errors='ignore')
if '\n' in buffer:
lines = buffer.split('\n')
buffer = lines[-1]
for line in lines[:-1]:
if line.startswith('data: ') and line != 'data: [DONE]':
try:
data = json.loads(line[6:])
content = data['choices'][0]['delta'].get('content', '')
if content:
print(content, end='', flush=True)
except:
continue
elif line == 'data: [DONE]':
print("\n")
break
conn.close()
# 使用示例
messages = [
{
"role": "user",
"content": "https://tuziai.oss-cn-shenzhen.aliyuncs.com/style/default_style_small.png 让这个女人带上墨镜,衣服换个颜色"
}
]
generate_image_with_chat_format(messages)
¶ 格式参数说明
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
model |
string | 是 | 模型名称,固定为 "flux-kontext-pro" |
messages |
array | 是 | 消息数组,包含用户的提示内容 |
stream |
boolean | 否 | 是否启用流式输出,默认为 true |
¶ Messages格式
{"model":"fal-ai/flux-pro/kontext","prompt":"https://tuziai.oss-cn-shenzhen.aliyuncs.com/style/default_style_small.png ","n":1,"size":"1024x1024","response_format":"url","controls":{}}

¶ API使用示例(base64传图)
"""
* 此脚本用于调用flux-kontext-pro模型,提交提示词和图片,并返回处理结果
* 支持无图、单图或多图(图片放在脚本通目录下)的情况
* 请确保已安装Python环境并安装requests库
* 确保output目录存在或脚本有权限创建该目录
* 脚本会尝试下载返回的图片并保存到output目录
"""
import os
import base64
import requests
import re
import json
# 配置参数
MODEL = "flux-kontext-pro"
API_URL = "https://api.tu-zi.com/v1/chat/completions"
API_TOKEN = "sk-yourkey"
# 提示词和输入图片,图片请放到和脚本同一目录
prompt = "For a new picture of a girl, add an animal picture to her clothes"
# 图片列表,可以包含多张图片
images = [
"girl.png",
"animal.png"
]
def prepare_image_data(image_path):
"""准备图片数据,转换为base64格式"""
try:
with open(image_path, "rb") as img_file:
encoded_data = base64.b64encode(img_file.read()).decode("utf-8")
return "data:image/png;base64," + encoded_data
except Exception as e:
print(f"准备图片数据时出错: {image_path} - {e}")
raise
# 构建消息内容
message_content = [{"type": "text", "text": prompt}]
# 添加图片到消息内容
for image_path in images:
try:
image_data = prepare_image_data(image_path)
message_content.append({
"type": "image_url",
"image_url": {"url": image_data}
})
except Exception as e:
print(f"处理图片时出错: {image_path} - {e}")
exit(1)
data = {
"model": MODEL,
"stream": True,
"messages": [
{
"role": "user",
"content": message_content
}
],
}
# 发送请求
headers = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
try:
response = requests.post(API_URL, json=data, headers=headers, timeout=1200, stream=True)
except Exception as e:
print(f"发送请求时出错: {e}")
raise
# 处理响应
if response.status_code != 200:
print(f"API 错误: {response.status_code} - {response.text}")
exit()
# 处理流式响应
all_content = ""
result_id = ""
download_count = 0
try:
for line in response.iter_lines():
if line:
line_text = line.decode('utf-8')
# 解析流式数据
if line_text.startswith('data: '):
data_content = line_text[6:] # 去掉 'data: ' 前缀
if data_content.strip() == '[DONE]':
break
try:
chunk_data = json.loads(data_content)
if "id" in chunk_data:
result_id = chunk_data["id"]
if "choices" in chunk_data and chunk_data["choices"]:
choice = chunk_data["choices"][0]
if "delta" in choice and "content" in choice["delta"]:
content = choice["delta"]["content"]
if content:
all_content += content
except json.JSONDecodeError:
continue
# 提取markdown格式的图片链接 
download_links = re.findall(r'!\[.*?\]\((https?://[^\s\)]+)\)', all_content)
if download_links:
print(f"找到 {len(download_links)} 个图片链接,开始下载...")
for idx, image_url in enumerate(download_links):
try:
image_data = requests.get(image_url).content
ext = "png"
m = re.search(r"\.([a-zA-Z0-9]+)(?:\?|$)", image_url)
if m:
ext = m.group(1).split("?")[0]
if len(ext) > 5:
ext = "png"
file_name = f"{result_id or 'noid'}-{idx}.{ext}"
output_dir = os.path.join(os.getcwd(), "output")
os.makedirs(output_dir, exist_ok=True)
output_path = os.path.join(output_dir, file_name)
with open(output_path, "wb") as f:
f.write(image_data)
print(f"图片已保存到: {output_path}")
download_count += 1
except Exception as e:
print(f"下载图片失败: {image_url} - {e}")
if download_count == 0:
print("未成功下载任何图片。")
else:
print(f"成功下载 {download_count} 张图片。")
except Exception as e:
print(f"处理响应时出错: {e}")
exit()
¶ 调用方式三:generations格式API
¶ 特点
- 支持完整的参数配置
- 更精确的控制选项
- 适合生产环境使用
¶ 完整示例
import http.client
import json
# 配置参数
def generate_image_with_full_params():
# 必填参数
PROMPT = "https://tuziai.oss-cn-shenzhen.aliyuncs.com/style/default_style_small.png 让这个女人带上墨镜,衣服换个颜色"
# 可选参数
payload_data = {
"model": "flux-kontext-pro",
"prompt": PROMPT,
"aspect_ratio": "16:9", # 图像宽高比
"output_format": "png", # 输出格式
"safety_tolerance": 2, # 安全容忍度
"prompt_upsampling": False # 提示上采样
}
# 可选:添加种子以获得可重复结果
# payload_data["seed"] = 42
# 可选:添加输入图像(Base64编码)
# payload_data["input_image"] = "base64_encoded_image_string"
conn = http.client.HTTPSConnection("api.tu-zi.com")
payload = json.dumps(payload_data, ensure_ascii=False).encode('utf-8')
headers = {
'Authorization': 'Bearer your-key',
'Content-Type': 'application/json; charset=utf-8'
}
try:
conn.request("POST", "/v1/images/generations", payload, headers)
res = conn.getresponse()
data = res.read()
print("API响应:")
print(data.decode("utf-8"))
except Exception as e:
print(f"请求失败: {e}")
finally:
conn.close()
# 调用函数
generate_image_with_full_params()
¶ Messages格式
{"data":[{"url":"https://fal.media/files/penguin/W7Sp0uVYy-YhXHU1mubri_61c8f15b665444ecac763a61eeffe05b.png"}],"created":1748915064}
¶ 标准API参数详解
¶ 必填参数
| 参数 | 类型 | 说明 | 示例 |
|---|---|---|---|
model |
string | 模型名称 | "flux-kontext-pro" |
prompt |
string | 文本提示,可包含图片URL | "一只可爱的猫咪" |
¶ 可选参数
| 参数 | 类型 | 默认值 | 说明 | 示例 |
|---|---|---|---|---|
input_image |
string | null | Base64编码的输入图像(方案三暂时不支持) | "data:image/jpeg;base64,..." |
seed |
integer | null | 随机种子,用于可重复生成 | 42 |
aspect_ratio |
string | "1:1" | 图像宽高比--需要原图比例的可以不传或者置空 | "16:9", "1:1", "9:16" |
output_format |
string | "jpeg" | 输出格式 | "jpeg", "png" |
webhook_url |
string | null | Webhook通知URL | "https://your-webhook.com" |
webhook_secret |
string | null | Webhook签名密钥 | "your-secret-key" |
prompt_upsampling |
boolean | false | 是否对提示进行上采样 | true, false |
safety_tolerance |
integer | 2 | 安全容忍度级别(0-6) | 0(最严格) - 6(最宽松) |
¶ 宽高比选项
支持的宽高比范围在 21:9 到 9:21 之间,常用选项:
"21:9"- 超宽屏"16:9"- 宽屏"4:3"- 标准屏幕"1:1"- 正方形"3:4"- 竖屏"9:16"- 手机竖屏"9:21"- 超长竖屏
¶ 使用技巧
¶ 1. 图像参考使用
在提示中可以直接包含图片URL:
prompt = "https://example.com/image.jpg 让这个人穿上红色衣服"
涉及多图的,按下列格式放入提示词即可(即URL按顺序放置在最前端,用空格隔开)
prompt=" https://tuziai.oss-cn-shenzhen.aliyuncs.com/style/default_style_small.png https://tuziai.oss-cn-shenzhen.aliyuncs.com/small/4-old.png Please replace the girl in P2 with the girl from P1."
¶ 2. 种子使用
使用相同的种子和提示可以生成相似的图像:
payload_data = {
"model": "flux-kontext-pro",
"prompt": "一只蓝色的猫",
"seed": 12345 # 固定种子
}
¶ 3. 安全容忍度调整
0-2: 严格模式,适合商业用途3-4: 平衡模式,适合一般用途5-6: 宽松模式,创意内容
¶ 联系支持
如有问题,请联系技术支持或查看API文档获取更多信息。